배경
최근 작은 동아리에 들어가게 됐다. 무슨 동아리인고 하면, 어떤 서비스를 기획해서 출시해보는 동아리이다. 어린 친구들이 대다수라 막 그렇게 대단히 전문적이지는 않고...
아무튼 나는 개발 경력이 있긴 하나 기획자의 역할로 들어갔고, 기획자라고는 하지만 마케팅부터 PO의 일까지 두루 겸하는 말 그대로 무근본의 무언가가 바로 내 역할이다.
나는 앱 기획 단계에서부터 참여한 게 아니라, 현재 이미 제작중인 앱이 있고(한 70% 완성된듯?) 나는 그 앱의 자잘자잘한 UI 따위를 기획하고 있다. 그런데 이 앱을 이제 플레이스토어/앱스토어에 런칭할 때 앱스토어에 어떻게 최적화할 것이냐 하는 문제가 대두되었고, 같이 기획 하는 친구랑 관련 스터디를 해보기로 했다.
사실 나 자신도 최근 개발을 끝마친 병맛 게임이 하나 있는데, 정말 놀랍게도 스토어에 이름 그대로 검색해도 노출이 안된다.
그렇다고 출시가 안 된 건 아니라 그냥 그만큼 공 굴리기 게임은 많고 내 앱은 최적화가 안되어있는 것이다. 뭐 따로 광고를 넣은 것도 아니니 트래픽 자체가 안나와서 기본적인 순위가 당연히 낮을 수밖에 없는 것이긴 하지만, 아무리 그래도 그렇지 이름 그대로 검색했는데 나오지 않는 건 좀 너무하지 않나?
아무튼 내 개인에게도 이런 사정이 있는만큼, ASO에 더욱 관심을 갖게 됐다.
You Got Balls: 3d Rolling Game - Google Play 앱
이 길의 끝엔 뭐가 있을까요? 도전 정신을 발휘해 공을 굴려 알아내보세요!
play.google.com
▲▲▲▲▲▲▲▲ 플레이해줘 ▲▲▲▲▲▲▲▲
관련 자료들
앱 스토어 최적화(ASO) 경험담 (1)
Part1. 키워드 최적화 (Keyword Optimization) | 구글 플레이 콘솔, 애플 앱스토어 커넥트에서는 우리 앱의 상세 페이지에 표시되는 내용들을 설정할 수 있습니다. 앱 이름, 아이콘, 스크린샷, 앱에 대한
brunch.co.kr
오가닉 유저 늘리기 출발점
공급자 입장에서의 스토어 콘솔말고, 유저 입장에서의 스토어에서 출발하기 | 본 글은 오가닉 그로스 실제 경험에 기반한 경험 공유 글입니다. 황무지를 개척하여 논밭을 일구기까지의 여러
brunch.co.kr
스토어 키워드 랭크 올리기
우리 앱이 스토어에서 잘 노출되었으면 좋겠어 (1) | 오가닉 유저 늘리기 출발점 - 공급자 입장에서의 스토어 콘솔말고, 유저 입장에서의 스토어에서 출발하기 지난 글을 통해 오가닉 유저를 늘
brunch.co.kr
일단 데이터를 정리해보자
데이터 수집이 먼저라고 판단했다. 그보다도 데이터를 정리하는 방법론의 수립이 필요하지 않을까?
뭘 모르겠을 때엔 남들이 어떻게 하고 있는지를 먼저 봐보는 것도 중요하다고 생각했다. 즉, 우리 앱의 기능 위주로 키워드를 검색한 다음, 상위에 노출되는 앱들이 어떤 키워드를 사용하고 있는지를 살펴보자는 것.
접근성이 좋은 플레이스토어 먼저 해봤다. 플레이스토어는 웹에서도 여러 앱들을 검색해볼 수 있어서, 나같은 사람들에겐 더 친화적이라고 할 수 있다. 앱스토어의 경우 앱 하나하나 구글링해서 검색할 수는 있지만(ex. '카카오톡 앱스토어'라고 검색하면 딱 그 카카오톡의 웹 페이지만 나온다), 플레이스토어처럼 따로 검색기능까지 제공하고 있는 것은 아니다.
일단 파이썬 코드를 짰다.
GitHub - rhdn520/aso
Contribute to rhdn520/aso development by creating an account on GitHub.
github.com
이 코드는 어떤 것이냐? 키워드 변수를 입력하면 해당 키워드로 플레이스토어에 검색을 하고, 그 결과에 나온 상위 10개 앱의 제목과 정보 부분을 크롤링해서 키워드를 추출하고, 나만의 뇌피셜 공식에 따른 키워드 점수까지 계산해 엑셀로 뱉어주는 녀석이다.

물론 내가 짰고, 뭐 세련되게 클래스화 해서 좀 더 범용성(?) 있게 만들수도 있겠지만 일단 저렇게 했다.
로직은 단순하다.
첫째, 전체 데이터에서 키워드를 뽑아내서 dictionary화 한다.
둘째, 각 앱 타이틀/상세설명 마다 각 단어의 비중을 softmax 함수로 표현해 정규화한다. (따라서 그 글에서 단 한번도 언급되지 않은 단어라도 그 값이 0이 아니다.)
셋째, 각 단어의 'Appearance Score'와 'Coincide Score'를 계산해
(Total Score) = (Appearance Score) - (Coincide Score)
의 공식으로 스코어를 계산한다.
Appearance Score 란 무엇이냐
일단 상위 10개 앱을 고른다고 했다. 그리고 모든 키워드는 dictionary 화 되어서 고유한 index를 부여받은 상태다.
그러면 이걸 행렬로 표현한다 치면, 단어개수 n 개일 때 n x 10 의 행렬이 만들어진다. 이때 열은 1열 최상위부터 10열 최하위까지 있는 상태이다.
플레이스토어는 기본적으로 동일한 단어를 많이 언급하면 그 키워드가 자주 검색된다는 조건 하에서 긍정적인 효과를 가져온다고 알려져있는데, 따라서 기본적으로는 각 텍스트에서의 언급 비중이 해당 순위에 긍정적인 영향을 미쳤을 것이라는 가정을 했다. 즉, 한 열 안에서 각 단어는 locally 긍정적인 영향을 미치는 것. 그러나 언급 비중이 높다고 그게 곧이곧대로(즉, 선형적으로) 긍정적인 영향을 미쳤을까? 그건 아니라고 봤다.
그래서 각 단어의 Appearance Score는 저 matrix에 [log(10), log(9), .... , log(1)]의 행렬을 곱한 값으로 했다. 당연히 log는 밑이 e이다.
즉 순위가 높아질 수록 각 단어의 효과를 좀 낮게 계산하고자 했던 것이다. 왜 log를 썼냐? 이유는 없다. 애초에 저 단어 목록을 정규화 할 때 softmax를 쓴 것도 이유는 없었다.
def calc_appearance_score(keyword_matrix):
log_n = np.log([10,9,8,7,6,5,4,3,2,1])
appear_score = np.matmul(log_n, keyword_matrix)
return appear_scoreCoincidence Score
그런데 위에서 언급했듯 동일한 단어가 또 너무 많이 함께 언급되는 경우엔 경쟁률이 빡세서 그 효과가 반감될 수 있다. 나는 역효과 수준까진 없다고 봤지만, 남들과 함께 언급되는 비율이 많다면 그 키워드의 유용성은 조금 떨어진다고 봐도 되지 않을까?
이 경우에 나는 남들과 다 같이 언급하는 비중이 클 수록 그 안좋은 효과가 exponential 하게 커질 거라고 봤다. 그래서 각 단어의 언급 비중 평균에 1.25 제곱을 했다. 그런데 이렇게만 하면 Appearance Score하고 값 차이가 너무 많이 나서 여기에 또 10을 곱했다.
def calc_coincide_score(keyword_matrix):
keyword_matrix = keyword_matrix ** 1.25
return np.average(keyword_matrix, axis=0) * 10Total Score
각 단어의 최종 점수는 Appearnce Score에서 Coincidence Score를 뺀 값으로 정의했다.
이렇게 하면 어떻게 나올까!!
일단 우리 동아리에서 만든 앱은 습관 형성 앱이다.
키워드 몇 개 넣어보자.
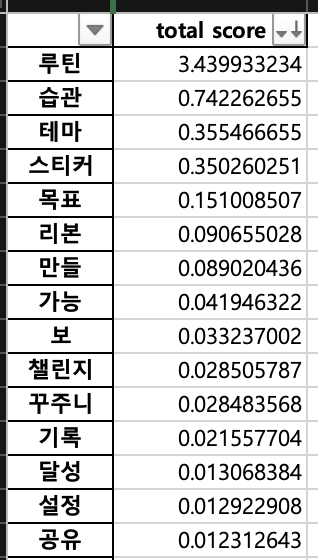


참고로 '하' 같은 단어는 동사 어근이라고 보면 된다. 설득력이 있어보이나? '갓생' 검색에 '스티커' 따위의 단어가 상위에 있는 건 꽤 재밌는 사실인 것 같다. '감정', '해마', '모드' 따위의 단어도 신기하다. 신기하긴 한데, 뭐 유용한지는 지금으로선 알 길이 없다. 여러 실험을 통해서 실제 순위 변화를 확인하면서 해야 하는데, 아직 앱 개발도 끝나지 않았으니...
의의....
일단 뇌피셜로 되도 않는걸 만들어봤다는 데에 의의가 있다.
프레임워크가 잡혀있으면 사실 세부적인 공식들이야 수정해나가면 그만이다.
또, 불용어 목록을 추가해두면 '광고'같은 안좋은 키워드를 뺄 수 있을 것 같다.
아 그리고 한국어 품사 태깅엔 Kiwipiepy 가 좋으니 다들 써보시길. 시대가 어느시댄데 아직도 mecab 이딴거 보고있는 양반들 있길래..
'기획' 카테고리의 다른 글
| 모임타임: 버그 수정 & 무료 광고 수합 (0) | 2024.03.19 |
|---|---|
| 모임타임: 약속시간을 정하는 웹사이트를 만들어보자 (0) | 2024.01.17 |


댓글